· AI Infrastructure · 10 min read
The CUDA Monopoly Breaks: Running Unmodified CUDA on AMD GPUs in 2026
SCALE and other CUDA-compatibility layers are cracking Nvidia's software moat, letting unmodified CUDA binaries run on AMD hardware. Here is what it means for AI inference costs and enterprise infrastructure in 2026.

- CUDA's moat is eroding: The SCALE language lets unmodified CUDA binaries run on AMD GPUs, breaking Nvidia's 15-year software lock-in.
- Cost disruption is real: Gartner forecasts AI infrastructure at over 45% of total $2.59T AI spend. GPU hardware competition directly impacts cost curves.
- Enterprise demand is shifting: PwC identifies GPU availability and cost as top-3 constraints on enterprise AI scaling. AMD + SCALE is a credible alternative.
- AI sovereignty drives adoption: Deloitte flags hardware diversity as a key component of sovereign AI infrastructure. SCALE makes AMD a viable option for government workloads.
- Performance skepticism remains: Real-world parity with native CUDA on Nvidia hardware is unproven at scale. Early adopters should benchmark aggressively.
For fifteen years, CUDA has been the gravitational center of GPU computing. Nvidia built it, owned it, and used it to create a software moat so deep that even superior hardware from competitors could not cross it. If your machine learning stack touched a GPU, it touched CUDA. If it touched CUDA, it touched Nvidia.
That assumption is now breaking.
The SCALE language and a growing ecosystem of CUDA-compatibility layers let developers run unmodified CUDA binaries on AMD GPUs. Not recompiled. Not ported. Not rewritten in HIP or ROCm. The same .ptx and .cubin files that were compiled for Nvidia hardware execute on AMD silicon with no source changes required.
This is not a laboratory experiment. It is shipping, documented, and being stress-tested in production environments today. And it changes the economics of AI infrastructure fundamentally.
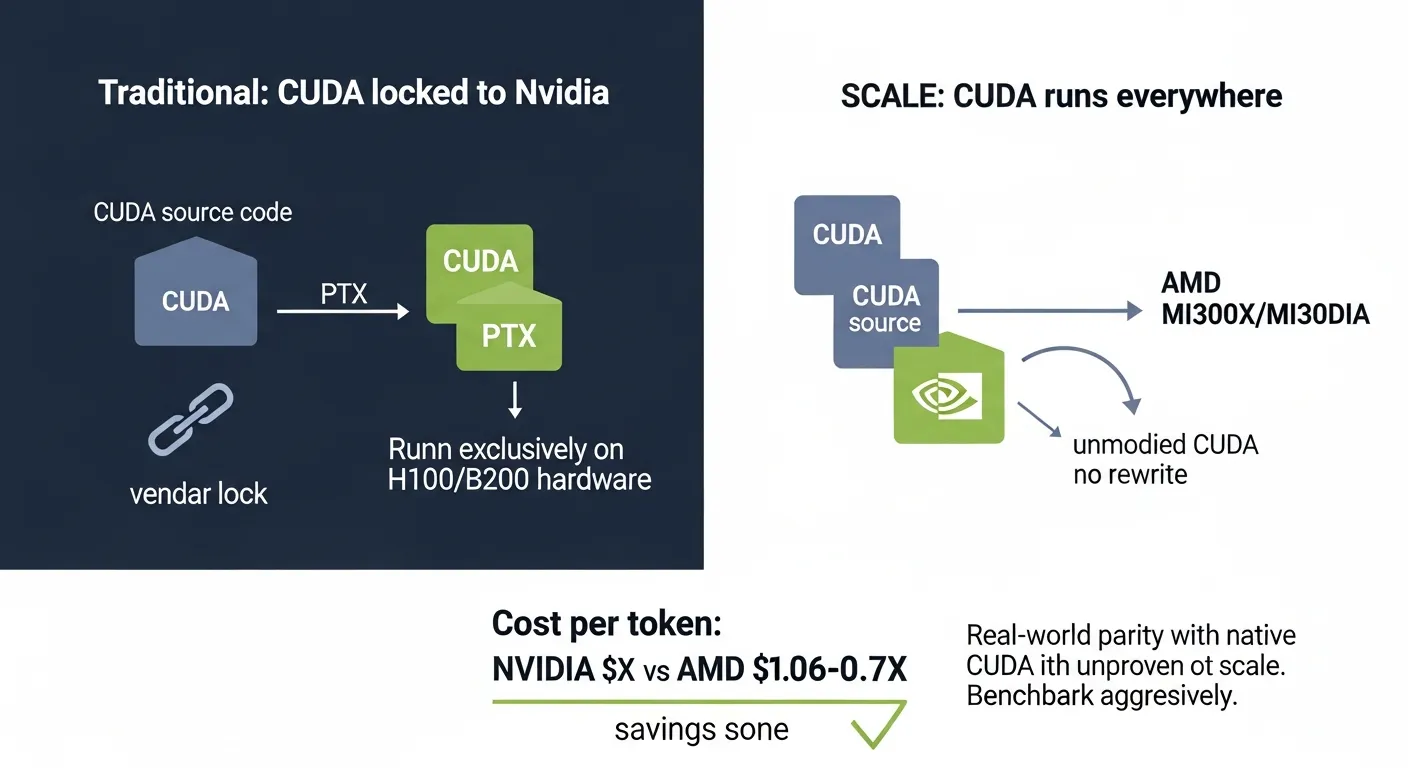
The SCALE Language: A New Compilation Target
SCALE is a GPU programming language and compiler toolchain developed by Spectral Compute. It implements the CUDA programming model as a language specification, meaning it accepts CUDA C++ source code and PTX (Parallel Thread Execution) intermediate representations directly. The compiler targets AMD’s CDNA and RDNA architectures, translating CUDA thread hierarchies, shared memory semantics, and synchronization primitives into AMD-native instructions.
What makes SCALE different from earlier CUDA-to-AMD translation efforts is its approach. Previous attempts like AMD’s HIP (Heterogeneous-Compute Interface for Portability) required developers to manually port CUDA code to a new API surface. HIP is a good piece of engineering, but it asks every open-source project and every internal codebase to maintain a separate code path. That creates friction, and friction kills adoption.
SCALE eliminates the friction entirely. You take your existing CUDA binary, point SCALE’s runtime at an AMD GPU, and it works. The implications are hard to overstate.
The PyTorch ecosystem, Hugging Face Transformers, vLLM, TensorRT-LLM, and dozens of other key AI infrastructure projects ship CUDA kernels as part of their distributions. Every single one of those kernels becomes portable to AMD hardware the moment SCALE reaches feature parity. No fork. No rewrite. No “AMD edition” that lags six months behind mainline.
Why This Matters for AI Inference Costs
The AI industry is spending money on GPUs at a pace that has no historical precedent. Gartner projects total AI spending will reach $2.59 trillion by 2027, with AI infrastructure accounting for over 45% of that figure. That is more than a trillion dollars flowing into hardware, data centers, and the power to run them.
Nvidia has captured the vast majority of that spend because it owns the only viable software stack for training and inference at scale. The H100 and B200 command premium pricing not just because they are fast, but because there is no alternative that runs the same software. AMD’s MI300X and the upcoming MI400 offer competitive FLOPS and memory bandwidth on paper. In practice, the software gap has kept them in a distant second place, even as their raw specifications close the gap generation over generation.
SCALE changes this calculus. If an enterprise can buy an AMD MI400 for 30-40% less than an equivalent Nvidia B200 and run the same CUDA binaries without modification, the TCO argument flips overnight. The GPU becomes a commodity again, at least for inference workloads where the software stack is already mature.
PwC’s 2025 AI Business Survey identified GPU availability and cost as two of the top three constraints on enterprise AI scaling, alongside data readiness. Enterprises want to deploy more AI, but they are bottlenecked by hardware supply chains that run through a single vendor. SCALE does not solve the supply problem, but it opens the door to a second supplier that can absorb demand that Nvidia cannot or will not serve at competitive prices.
The AMD Moment
AMD has been fighting the software perception battle for years. ROCm, their open-source GPU computing platform, has matured significantly. Support for PyTorch and TensorFlow is better than it was in 2023. But ROCm adoption has always been hampered by a chicken-and-egg problem: developers will not target a platform that lacks users, and users will not buy hardware that lacks software support.
SCALE breaks that deadlock by not asking developers to adopt anything. It meets them where they already are, in the CUDA ecosystem, and makes their existing code work on AMD hardware.
For AMD, this is transformative. The company can now compete on hardware merit rather than ecosystem lock-in. The MI300X already matches or exceeds the H100 in raw FP8 and FP16 throughput for specific workloads. The MI400, expected in late 2026, targets the B200’s performance class with higher memory bandwidth and lower power draw per teraFLOP. If those specifications hold, and SCALE delivers production-quality CUDA compatibility, AMD becomes a viable alternative for the first time in a decade.
The strategic importance for AMD is clear. Data center GPU revenue is the fastest-growing segment of their business, and SCALE removes the single biggest barrier to capturing enterprise wallet share. Lisa Su’s team has been clear that ROCm remains their long-term platform strategy, but SCALE serves as an immediate bridge that lets AMD sell hardware today rather than waiting for native ecosystem adoption to materialize.
AI Sovereignty and the Open-Source Argument
Deloitte’s 2025 Tech Trends report identifies “AI sovereignty” as a rising leadership priority for governments and regulated industries. The concept is straightforward: nations and enterprises want control over their AI infrastructure, including hardware sourcing, software stack, and data governance. Dependence on a single silicon vendor for compute creates a geopolitical vulnerability that governments are increasingly unwilling to accept.
SCALE is open-source, or at least source-available under a license that permits auditing and modification. For governments concerned about supply chain security, this matters. For enterprises building AI infrastructure in regulated verticals like healthcare, finance, and defense, it provides an alternative to Nvidia’s proprietary stack.
The open-source argument extends beyond sovereignty. SCALE’s approach to CUDA compatibility creates a more competitive GPU market, which drives down prices and increases innovation velocity across the entire stack. This is the same dynamic that Linux brought to operating systems and Kubernetes brought to orchestration. When the software layer becomes portable, the hardware layer becomes a commodity. GPU prices follow the same curve that server prices followed in the 2010s: down, and to the right.
What the Community is Saying
Reactions across the AI community range from cautious optimism to outright enthusiasm, with a healthy dose of skepticism mixed in.
On r/LocalLLaMA, SCALE is widely discussed as the most promising CUDA competitor to emerge in years. The subreddit, which focuses on running large language models locally, sees SCALE as a potential unlock for AMD GPU owners who have been stuck with second-class software support. Running Llama 3 or Qwen on AMD hardware at close to Nvidia performance without maintaining a separate build is the kind of pain point that resonates deeply with this community.
r/AMD discussions focus more on the implications for ROCm adoption. Some community members worry that SCALE could fragment the AMD GPU software ecosystem rather than unify it. If developers target SCALE instead of ROCm, AMD’s native platform could atrophy, recreating the same dependency problem with a different vendor. Others argue that SCALE’s CUDA compatibility is a bridge, not a destination, and that ROCm remains the right long-term investment for AMD-specific optimizations.
The skepticism is real and worth taking seriously. SCALE has demonstrated compelling demos on individual workloads, but the CUDA ecosystem is vast. Optimized kernels for FlashAttention, MoE routing, speculative decoding, and dozens of other inference optimizations rely on CUDA-specific features that may not translate perfectly to AMD hardware. Real-world inference performance at scale across diverse model architectures is the metric that matters, and the data is still being collected.
Performance Parity is Not Guaranteed
This is the honest counterargument that every enterprise evaluating SCALE needs to weigh carefully.
CUDA has been tuned for Nvidia hardware for over a decade. Nvidia’s compiler engineers have optimized every instruction path, every memory access pattern, and every thread scheduling decision for their specific architecture. SCALE can translate CUDA semantics correctly and still produce code that is 10-20% slower on AMD hardware than the original binary was on Nvidia hardware, simply because the AMD backend has not received the same decade of tuning.
For inference workloads, this performance gap might be acceptable. Inference is typically less sensitive to peak FLOPS than training, and the cost savings from AMD hardware can offset modest throughput differences. A 15% throughput reduction combined with a 35% hardware cost reduction still yields a favorable cost-per-token outcome.
For training workloads, the calculus is different. Training involves complex distributed communication patterns, gradient synchronization, and long-running jobs where throughput differences compound over days or weeks. A 20% training throughput gap is painful, especially in multi-node configurations where all-to-all communication, NCCL equivalents, and ring topology optimizations need to be mapped correctly.
SCALE’s roadmap addresses these concerns. The team at Spectral Compute is working on NCCL-compatible collectives, improved PTX coverage, and workload-specific tuning guides. But roadmaps are not reality. Enterprises should benchmark their specific workloads on SCALE before making procurement decisions, and they should maintain the ability to fall back to native Nvidia hardware if performance does not meet requirements.
The Bottom Line for Enterprise AI Leaders
If you are responsible for AI infrastructure decisions in 2026, SCALE and CUDA-compatibility layers deserve a spot on your evaluation shortlist. Not as a replacement for Nvidia overnight, but as a strategic hedge that gives you negotiating leverage and supply chain flexibility.
Here is the practical framework I recommend:
First, identify your inference workloads and evaluate whether they are good candidates for SCALE. High-throughput serving of standard transformer architectures is the sweet spot. Exotic kernels, custom CUDA extensions, and untested model families should be validated before committing.
Second, run your own benchmarks. Do not rely on published performance numbers from Spectral Compute or community benchmarks on r/LocalLLaMA. Your model, your traffic patterns, your latency requirements. Set up a test cluster with AMD MI300X or MI400 hardware, install the SCALE runtime, and measure cost-per-token versus your Nvidia baseline. The data will tell you whether the tradeoff works for your use case.
Third, engage with AMD and Spectral Compute directly. The SCALE ecosystem is evolving fast, and the gap between what is possible today and what will be possible in Q4 2026 is significant. Understanding the roadmap helps you make informed decisions about when to commit.
Fourth, maintain optionality. The worst outcome in infrastructure is lock-in, whether to Nvidia or AMD. Design your deployment pipeline so that swapping GPU targets requires configuration changes rather than code changes. Use abstraction layers like vLLM or TGI that support multiple backends. Treat GPU targets as a deployment parameter, not an architectural commitment.
The CUDA monopoly is breaking. It will not break overnight, and Nvidia will not surrender its position quietly. Blackwell Ultra and Rubin architectures will push performance forward, and Nvidia’s software engineering team remains the best in the industry. But the era of unconditional CUDA lock-in is ending, and that is good news for everyone building AI infrastructure.
Competition reduces costs, increases innovation velocity, and gives buyers choices. SCALE gives the AI industry a credible path to hardware diversity. Enterprises that prepare for that future now will be the ones that capture the cost advantages when the transition accelerates.
The GPU market is becoming a market again. Plan accordingly.



