· Strategy · 11 min read
The Democratization of Quant Finance: How Open-Source AI Is Reshaping Wall Street
Open-source AI-driven stock analysis tools are putting hedge-fund-grade quantitative analysis in every developer's terminal - and forcing traditional quant firms to rethink their moats.

- The Quant Moat Is Cracking: Open-source AI repositories like ZhuLinsen/daily_stock_analysis now deliver capabilities that would have cost millions in proprietary infrastructure just five years ago, eroding the traditional competitive advantage of quantitative hedge funds.
- ROI Validation Is Real: KPMG's 2026 Global AI in Finance report shows 71% of financial organizations report AI meeting or exceeding ROI expectations, with decision-making quality (70%) and forecasting accuracy (64%) as the top drivers.
- Agent Spending Is Accelerating: Gartner forecasts AI spending in financial services to reach $206.5 billion in agent software alone by 2026, signaling that the industry is placing massive bets on autonomous financial analysis.
- Open Source Is the New R&D Lab: The most interesting quant innovation is increasingly happening in public GitHub repositories rather than behind proprietary firewalls, challenging the "secret sauce" model that defined Wall Street for decades.
- The Risk Hasn't Disappeared: The democratization of quant tools introduces new risks around model overfitting, backtest manipulation, and the illusion of precision - especially for retail investors who lack the institutional context to evaluate strategy quality.
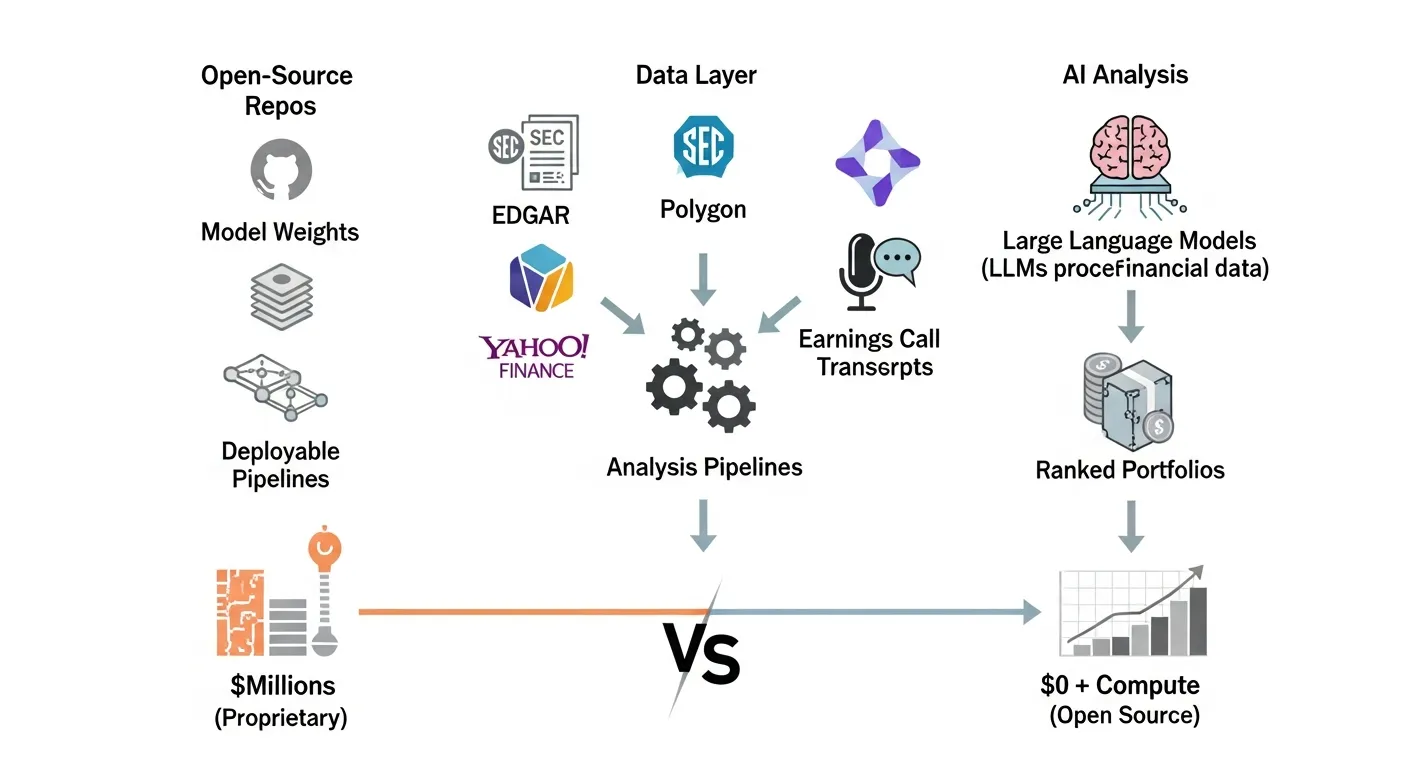
Last month, I cloned a GitHub repository with an unassuming name: ZhuLinsen/daily_stock_analysis. Within an hour, I had a locally running pipeline ingesting price data, running sentiment analysis across financial news feeds, generating technical indicators, and producing a ranked list of overweight recommendations. It cost me nothing but compute time.
Five years ago, a system like this would have required a Bloomberg terminal subscription, a dedicated data engineering team, and a Quant developer making half a million dollars a year. Today, it is a git clone command away.
That gap between what used to require institutional infrastructure and what can now be done on a laptop now in financial services. And it is reshaping the competitive dynamics of an industry built on information asymmetry.
The Great Leveling: What Open Source Actually Unlocks
I have been following the open-source quant movement since the early days of Zipline and QuantConnect. Early frameworks were useful for backtesting, but they were a long way from production-grade analysis. The data connectors were fragile. The machine learning integrations required manual plumbing. You still needed significant domain expertise to get anything useful out of them.
The landscape today is fundamentally different. The combination of three converging trends has created a step change in capability.
First, large language models have become genuinely useful as analysis interfaces. Models like Llama 4 and DeepSeek can ingest an earnings call transcript and summarize the key risk factors in plain language, then generate executable Python code to test those risks against historical data. The model becomes both analyst and programmer.
Second, the data layer has opened up. Polygon, Tiingo, and Yahoo Finance provide API access to market data that was locked behind six-figure terminal subscriptions a decade ago. Alternative data sources like SEC EDGAR filings, Fed statements, and earnings call transcripts are all freely accessible through government APIs. The raw material of quant research is no longer scarce.
Third, the open-source ecosystem has matured into something resembling an operating system for financial analysis. Repositories like daily_stock_analysis do not just provide a single model or notebook. They provide a complete pipeline: data ingestion, feature engineering, model training, backtesting, and reporting. They include configuration files, Docker setups, and CI/CD pipelines. They are designed to be deployed, not just studied.
In my experience working with financial technology teams, this last point is the most significant. The shift from “here is a research paper” to “here is a deployable system” collapses the gap between idea and execution. And that collapse has direct competitive implications.
The $206 Billion Bet: Why Institutions Are All In
It would be easy to dismiss the open-source quant movement as a hobbyist phenomenon. The data from institutional spending suggests otherwise.
Gartner’s latest forecast projects that AI spending in financial services will reach $206.5 billion for agent software alone by the end of 2026. This is not experimental budget. This is production infrastructure spending. Banks, asset managers, and hedge funds are placing a bet that autonomous AI agents will become the primary interface for financial analysis, research, and even execution.
The KPMG 2026 Global AI in Finance report provides the counterpoint to the skepticism. Surveying over 1,200 financial organizations globally, KPMG found that 71% report AI initiatives meeting or exceeding their ROI expectations. The two areas where AI delivers the most value are decision-making quality (70% of respondents reporting improvement) and forecasting accuracy (64%). These are not peripheral metrics. They are the core outputs of the entire quant finance discipline.
What this tells me is that the ROI question has been settled at the institutional level. AI-driven analysis works well enough that organizations are betting their budgets on it. The question is no longer whether to adopt AI for quant finance. It is how to get the best AI-driven analysis without paying the premium for proprietary infrastructure.
That question is exactly what the open-source ecosystem answers.
The Proprietary Moat and Why It Is Drying Up
Traditional quant firms have relied on a simple competitive moat: they own things that others cannot afford. Proprietary data feeds, custom execution infrastructure, and decades of accumulated research that cannot be replicated without the same institutional history.
That moat is drying up for three reasons.
The data advantage is shrinking. Public markets generate public data. While high-frequency trading still depends on low-latency feeds, the vast majority of systematic strategies operate on daily or intraday timeframes. For these strategies, the difference between a $30,000-per-year data subscription and a free API is negligible, especially when the free API provides the same closing prices, volumes, and corporate actions.
The talent advantage is shifting. The best quantitative researchers I know are not all at hedge funds anymore. Many are publishing on arXiv, contributing to open-source projects, and building their own analysis frameworks in public. The open-source model attracts talent precisely because it offers visibility, portfolio-building, and intellectual freedom that proprietary environments often restrict.
The infrastructure advantage is commoditizing. Cloud computing, GPU instances, and managed Kubernetes clusters mean that a two-person team can now access compute resources that would have required a dedicated data center operation in 2015. The barrier to entry for running sophisticated models at scale is lower than it has ever been.
I am not arguing that traditional quant firms are doomed. The best firms have brand, talent density, and risk management discipline that open-source tools cannot replicate. But the structural advantage of “we can do things smaller players cannot afford” is eroding quarter by quarter.
How the Community Is Using These Tools
The discussion around open-source quant AI is no longer confined to obscure GitHub issues. It is happening in the open, and the sentiment is revealing.
The conversation around LLM-based trading agents has shifted noticeably in the last year. Early posts were skeptical, focused on the risks of overfitting and the inability of language models to handle non-stationary market dynamics. The current discussions are more pragmatic. Users report using LLMs for feature extraction from alternative data sources, generating alpha signals from earnings call sentiment, and building natural language query layers over their backtesting frameworks. The consensus is not that LLMs replace quantitative models. It is that they augment the research process in ways that were previously impossible without a large team.
The recurring concern is backtest overfitting, and it is a legitimate one. An open-source repository can produce beautiful backtest results that are entirely useless in production because the author inadvertently introduced lookahead bias, survivorship bias, or simply optimized too many parameters against historical data. I have seen this pattern repeatedly. The availability of sophisticated tools without corresponding risk awareness is a genuine danger.
However can LLMs genuinely model market dynamics, or do they simply surface known patterns in more convincing language? This is a version of the old debate between fundamental and technical analysis, updated for the AI era. My view is that LLMs are excellent at pattern recognition and synthesis but should not be trusted for causal inference about markets. They can tell you what has happened and what tends to happen next in similar conditions. They cannot tell you why the market will move tomorrow.
The Sentiment Debate
The optimistic camp sees open-source quant AI as the great equalizer. They point to specific wins: a developer in India using a locally deployed model to analyze Nifty 50 earnings calls; a team in Brazil building a sentiment-driven strategy around Petrobras news; a student in Singapore publishing research on volatility forecasting that gets cited by an academic journal. These stories are real, and they are accumulating.
The skeptical camp warns that easy access to sophisticated tools creates an illusion of competence. A beautifully plotted backtest with a Sharpe ratio of 3.5 is easy to produce when you can test 50 strategy variations and only publish the best one. The same tools that democratize analysis also democratize self-deception. Retail investors who adopt these tools without understanding the statistical pitfalls risk real capital.
I think both camps have valid points. The democratization of quant finance is unequivocally positive for the industry in the long run. More participants, more diverse strategies, and more transparent research make markets more efficient. But the transition period will see real losses from people who mistake tool access for domain expertise.
What This Means for Financial Services Strategy
For financial services leaders, the rise of open-source quant AI presents both a competitive threat and a strategic opportunity.
The threat is straightforward: if your quant strategy relies on proprietary tools and data that are increasingly available for free, your cost structure is out of alignment with the market. I have consulted with firms whose research budgets run to eight figures annually, with large portions allocated to data feeds and analytics platforms that now have viable open-source alternatives. The CFO conversation is coming, and it will be uncomfortable.
The opportunity is more interesting. Open-source tools reduce the cost of experimentation. Firms that embrace the open-source ecosystem can run more strategies, test more hypotheses, and iterate faster than firms that insist on building everything in-house. The strategic advantage shifts from ownership of infrastructure to mastery of execution and risk management.
The winning firms in the next decade will be those that build a layer of proprietary insight on top of open infrastructure, rather than trying to own the entire stack. They will use open-source tools for data ingestion, feature engineering, and baseline modeling. They will differentiate on portfolio construction, risk controls, and the human judgment that no model can replace.
The New Wall Stack
I have started calling this architecture the “New Wall Stack.” It has three layers.
At the base is open-source infrastructure: GitHub repositories for data pipelines, backtesting frameworks, and model deployment. This layer is free, constantly improving, and maintained by a global community.
In the middle is proprietary data and modeling: the specific signals, alternative data sources, and ensemble techniques that a firm develops internally. This is where competitive advantage is built, not in owning the pipeline but in knowing which data matters and how to combine it.
At the top is judgment and execution: portfolio construction, risk management, trade execution, and the human decisions about when a model’s output should be trusted, overridden, or ignored. This layer is the hardest to replicate and the most valuable.
Firms that understand this stack are already reorganizing their technology teams. They are hiring engineers who contribute to open-source projects rather than engineers who only work on internal tools. They are reducing spend on proprietary data platforms and increasing spend on talent that can extract insight from open data sources. They are treating their GitHub contributions as a recruiting signal rather than a security risk.
Conclusion
The democratization of quant finance is not a future trend. It is happening now, in public GitHub repositories that anyone can clone, study, and deploy. The tools that once separated institutional investors from retail participants are becoming commodities, and the strategic question for every financial services firm is what they will build on top of that commoditized foundation.
I believe the firms that thrive will be those that accept the commoditization of the infrastructure layer and focus their differentiation on the things that truly matter: proprietary insight, risk discipline, and judgment. The firms that try to maintain the old moats of data scarcity and computational exclusivity will find themselves defending a position that no longer exists.
The code is open. The data is accessible. The models are free. What remains is the hardest part: knowing what to do with them.



