· AI Engineering · 12 min read
The Open Source AI Tipping Point: Open Weights, Data Provenance, and What Still Locks In
Open-weight models from Meta, Mistral, and the Llama 4 ecosystem have shifted the AI debate from "open vs. closed" to a more nuanced question: what does open source actually mean when the training data remains invisible?

What matters right now:
- Open-weight models have won the mindshare war: Llama 4, Gemma 4, Mistral Large 3, and dozens of fine-tuned derivatives now match or exceed closed-source peers on key benchmarks.
- The real battle has shifted from model access to data transparency and the right to modify. Open weights without open data is a new kind of lock-in.
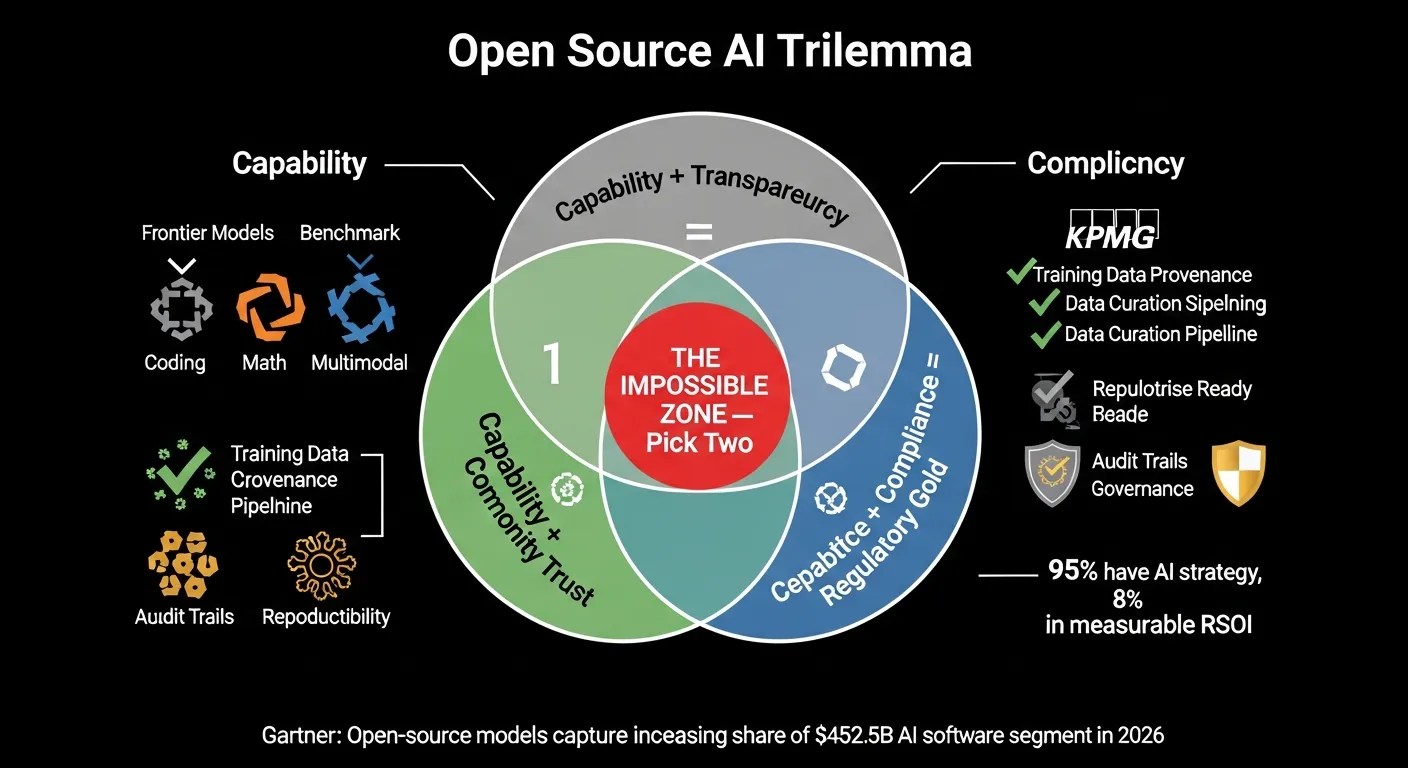
- Enterprises adopting open-source AI must navigate a trilemma: capability, transparency, and compliance. You can pick two today.
- Governance gaps remain the primary barrier for regulated industries, per McKinsey’s 2026 AI Trust Survey. The technology is ready; the audit trail is not.
For the better part of three years, the AI industry has been locked in a binary shouting match. Open source versus closed source. Meta versus OpenAI. The people’s model versus the corporate API. It made for good conference panels and better Twitter threads, but the framing was always too simple.
Now we see that debate is settling - not because one side won, but because the landscape has shifted beneath both. Open-weight models now dominate the conversation. Llama 4, Mistral Large 3, Qwen 3, DeepSeek V4, and a long tail of community fine-tunes have eroded the capability gap that kept enterprises locked into proprietary APIs. Gartner’s latest numbers tell the story: worldwide AI spending hit 452.5 billion AI software segment. The question is no longer whether open-source AI can compete. It can. The question is whether “open source” in AI means what we think it means.
The Open Weight Triumph
Let me start with what has actually been achieved, because it is substantial. The release of Llama 4 by Meta in early 2026 marked a genuine inflection point. For the first time, a model with competitive reasoning capabilities across coding, mathematics, and multimodal tasks was available as open weights under a permissive license. Not a “research preview” with strings attached. Not a weights-and-biases embargo. A model you could download, run on your own infrastructure, fine-tune, and deploy.
Mistral followed with Mistral Large 3, pushing the frontier further on long-context reasoning and tool use. DeepSeek continued its trajectory with V4, demonstrating that Chinese AI labs could produce open-weight models that rivaled anything coming out of Silicon Valley. The community ecosystem around these models exploded. Threads comparing inference speeds across consumer GPUs, quantization strategies, and fine-tuning recipes became the new normal. Running a frontier-class model locally is no longer a hobbyist curiosity. It is a production strategy.
The implications for enterprise AI architecture are profound. When you can download a model and run inference on-premises or in your own VPC, you eliminate the data exfiltration risk that has been the single biggest blocker for regulated industries. You decouple your AI capabilities from API pricing volatility. You gain the ability to fine-tune on proprietary data without sending embeddings to a third party. These are not theoretical advantages. They are driving real procurement decisions.
KPMG’s Global AI Pulse survey from Q2 2026 reports that 95 percent of organizations now have a formal AI strategy. Among them, the shift toward open-weight models is being driven primarily by two factors: flexibility and cost avoidance. Organizations want the option to switch providers, to run workloads on different hardware, to escape the gravity well of a single cloud API. They are not necessarily seeing better raw performance from open models. They are buying optionality.
The same survey carries a sobering caveat. Only 8 percent of organizations have established measurable ROI from their AI investments. Open-source adoption, in other words, is partly a hedge. It is driven by fear of lock-in rather than proven returns. That does not make it the wrong move. But it does mean the industry is still in what I would call the “infrastructure phase” - building capacity and optionality before the efficiency phase arrives.
Open Weights Are Not Open Source
Here is where the conversation gets uncomfortable. The term “open source” has been applied so loosely to AI models that it has nearly lost its meaning. The Open Source Initiative’s formal definition of open source requires free redistribution, access to source code, and the right to create derived works. By that standard, almost no modern AI model qualifies.
What we have is open weights. That is different. An open-weight model gives you the trained parameters. You can run it, fine-tune it, and in many cases redistribute it. But you cannot inspect the training data. You cannot reproduce the training process. You cannot audit the data curation decisions that shaped the model’s behavior. You are taking the model on faith.
This is not an abstract philosophical complaint. It has concrete consequences. When a model exhibits biased behavior on a specific demographic dimension, open weights do not help you diagnose why. The bias is baked in during training, and without access to the training distribution, you are left running behavioral tests in the dark. When a model’s performance degrades on a particular domain, you cannot trace the regression to a data sourcing decision. You can only observe the symptom.
The ML community has been debating this relentlessly. Its not uncommong to queestion “If I cannot inspect or reproduce the training data, does an open-weight model actually enable reproducibility in the scientific sense?” The consensus is clearly a no. Reproducibility requires transparency at every layer of the stack - data sourcing, filtering, tokenization, training configuration, evaluation methodology. Open weights address only the final artifact.
Meta has borne the brunt of this criticism, and not without reason. The company’s marketing around Llama has consistently used the language of openness while maintaining strict control over the training data. The Llama 4 technical report, while more detailed than its predecessors, still omits critical information about data mixtures, deduplication strategies, and filtering criteria. The term “open washing” has become a standard critique. Every Llama release is accompanied by heated debate about whether Meta deserves credit for advancing open AI or criticism for exploiting the label while serving its commercial interests.
Mistral has taken a slightly different approach. The company’s model cards are more transparent about architecture decisions and training configurations. But Mistral also keeps its data provenance close to the chest. The tension is structural. Training data is increasingly viewed as a proprietary moat. Companies that invest heavily in data curation are reluctant to publish their recipes, because those recipes are a competitive advantage.
The Trilemma
This brings us to what I see as the central strategic challenge for enterprise adopters: the open-source AI trilemma. You can have capability, transparency, and compliance. Pick two.
If you pick capability and transparency, you get a model that performs well and whose training process you understand, but that may not meet regulatory requirements for auditability and bias testing. This is the position of most organizations using open-weight models today.
If you pick capability and compliance, you get a model that works and satisfies regulatory checkboxes, but whose inner workings remain opaque. This is the position of enterprises that use closed-source APIs with contractual SLAs on security and compliance. You get the audit certificate. You do not get the truth.
If you pick transparency and compliance, you get a model you can fully audit and that meets regulatory standards, but that may lag behind the capability frontier. This is the position of organizations building fully open models from scratch using only publicly documented data. Few can afford this path.
The trilemma is not permanent. It reflects the current maturity of the ecosystem. But it is the reality enterprises face today, and ignoring it leads to bad decisions.
The Data Provenance Problem
The deepest unresolved issue in open-source AI is data provenance. We are training models on internet-scale datasets that are themselves assembled through opaque processes. CommonCrawl snapshots, filtered, deduplicated, and reweighted through pipelines that are rarely documented in sufficient detail. The result is a training corpus whose contents no single person fully understands.
This matters because model behavior is fundamentally a reflection of training data. When a model refuses a legitimate request, it is usually because of a filtering decision made during data preparation. When a model exhibits a stubborn factual error, it is usually because the training data contained contradictory information that was not properly resolved. When a model generates harmful output despite extensive safety fine-tuning, it is usually because the base model learned patterns during pre-training that RLHF cannot fully suppress.
Without data provenance, every model deployment carries unknown and unknowable risks. You are flying on an aircraft whose maintenance logs you cannot read. The engine is powerful. The flight is smooth. But you do not know what happened during assembly.
Several initiatives are working to address this. The Data Provenance Initiative, led by a consortium of academic and industry researchers, is building standards for documenting training datasets. The Open LLM leaderboard has started incorporating transparency scores alongside performance metrics. Hugging Face has pushed for standardized model cards with explicit data provenance sections. These are positive steps, but they remain voluntary. The models that dominate enterprise adoption - Llama 4, Mistral Large 3, Qwen 3 - all have incomplete provenance documentation.
What Still Locks In
Even as open-weight models remove one layer of lock-in, new forms of dependency emerge.
Hardware optimization is the most visible one. Llama 4 runs efficiently on Nvidia hardware, but its performance characteristics on AMD, Intel, or specialized AI accelerators vary dramatically. The model is open. The optimization stack is not. If you build your infrastructure around one model family, you may find yourself locked into a specific hardware ecosystem to maintain performance.
Fine-tuning infrastructure is another. The ecosystem of tools for fine-tuning Llama models - Unsloth, Axolotl, TRL, and the rest - is heavily oriented toward the Llama architecture. If you invest deeply in Llama-specific fine-tuning pipelines, you face switching costs if you want to move to Mistral or Qwen. The models are open. The tooling is semi-open. The switching costs are real.
Deployment tooling creates a third layer. vLLM, SGLang, TGI, and Ollama all support multiple model architectures, but the depth of integration varies. Performance optimization, quantization support, and feature completeness are uneven. The practical effect is that your choice of deployment framework becomes a lock-in mechanism, even if the models themselves are portable.
Then there is the ecosystem question. The strength of the Llama ecosystem - community fine-tunes, LoRA adapters, evaluation benchmarks, third-party tooling - creates a gravitational pull that is difficult to resist. Mistral and Qwen have their own ecosystems, but they are smaller. The network effects of model popularity create a de facto standard, and de facto standards are their own kind of lock-in.
The Strategy for Enterprise Adopters
Given all of this, what should an enterprise AI team actually do?
First, treat open-weight models as a necessary but insufficient condition for AI autonomy. Open weights eliminate API dependency, but they do not eliminate the need for rigorous evaluation, ongoing monitoring, and investment in internal AI infrastructure. Downloading Llama 4 and running it on a GPU instance is not a strategy. It is a starting point.
Second, invest in data provenance as a core competency. The organizations that will win with open-source AI are the ones that build their own evaluation datasets, document their own fine-tuning data, and maintain clear lineage for the data that shapes their models. If you cannot answer the question “what data went into this model and why,” you cannot manage the risk.
Third, build for portability. Use abstraction layers that allow you to swap model backends without rewriting your application. Invest in tooling that supports multiple model architectures. Test your workloads across providers and hardware platforms. The value of open weights is maximized when you maintain the ability to actually switch.
Fourth, participate in the governance conversation. The gaps in data provenance and training transparency will not be closed by waiting. They will be closed by pressure from enterprise buyers who demand better documentation. McKinsey’s 2026 AI Trust Maturity Survey identifies governance gaps as the primary barrier to open-source model adoption in regulated industries. That is not a technology problem. It is a market failure. Enterprise buyers have the leverage to fix it.
The Bottom Line
The open-source AI tipping point has arrived, but not in the way the early debates predicted. Open weights have won. The capability gap has narrowed to the point where proprietary models can no longer command a premium on performance alone. Enterprises are adopting open-weight models at scale, driven by flexibility, cost avoidance, and the desire to control their AI destiny.
But the deeper promise of open source - transparency, reproducibility, community governance - remains unfulfilled. The industry has delivered open artifacts without open processes. We have the weights. We do not have the data. We can run the models. We cannot audit them. The right to modify exists in theory but is constrained by ecosystem dependencies in practice.
The next phase of the open-source AI story will be about closing this gap. It will be about data provenance standards that make transparency a competitive requirement rather than a nice-to-have. It will be about tooling ecosystems that enable genuine portability across models and hardware. It will be about enterprise buyers demanding - and paying for - the documentation and auditability that regulated industries require.
The tipping point was never going to be a single model release or a single capability milestone. It was going to be the moment when the industry realized that open weights are necessary but not sufficient. We have reached that moment. Now the real work begins.



