· Deep Tech · 8 min read
Speculative Decoding Infrastructure: Squeezing Latency without Hardware Upgrades
The bottleneck for LLMs is memory bandwidth, not compute. Discover how to use speculative decoding on GCP to achieve 3x speedups by using small "draft" models to accelerate massive "oracle" models.

We are living in an era where we have more compute than we know how to use, but less memory bandwidth than we need.
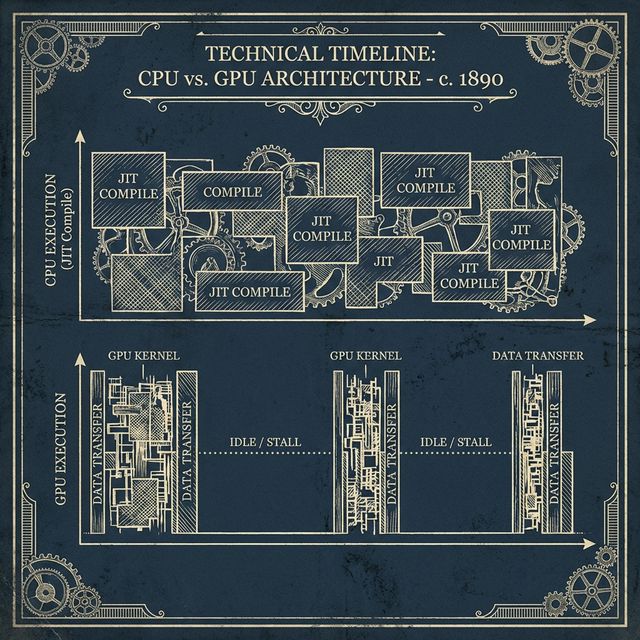
If you profile a Large Language Model (LLM) during inference, you will find something counter-intuitive. Your GPUs or TPUs are likely only working at 20% to 30% of their peak TFLOPS. The rest of the time, the chip is literally sitting idle, waiting for the model weights to be fetched from memory for every single token produced. This is the Memory Bandwidth Wall.
In a traditional “Autoregressive” decoding loop, the model generates one token at a time. To generate the word “Apple,” the model must load all 70 billion parameters (if using Llama 3 70B) to produce the ‘A’, then load all 70 billion again to produce the ‘p’, and so on. It is a massive, inefficient waste of resources.
But what if we could predict the next five tokens in a single pass? This is the core idea behind Speculative Decoding. Today, it is the most useful infrastructure optimization you can implement to slash your latency.
The Draft and the Oracle: A Tale of Two Models
Speculative Decoding works by introducing two distinct models into your inference pipeline: a Draft Model and an Oracle Model.
The Draft Model is small and incredibly fast (e.g., a 7B model or even a specialized Gemini Flash-distilled model). It is “cheap” to run because its weights fit easily into the L2 cache of the GPU. The Oracle Model is the massive, state-of-the-art model (like Gemma 2 or even a larger reasoning model) that you actually want to use for the final answer.
The process is a dance of speculation and verification:
- Speculation: The Draft Model quickly “guesses” the next N tokens (say, 5 tokens). Because it is small, it can do this in the time it would take the Oracle model to produce half a token.
- Verification: The 5 tokens are bundled together and sent to the Oracle Model in a single “Batch” pass.
- Acceptance: The Oracle checks the math. If its own probability distribution matches the Draft Model’s guesses for the first 3 tokens, those 3 tokens are accepted and immediately returned to the user. The 4th token (where they disagreed) is discarded, and the Oracle produces the correct 4th token.
The result? You have generated 4 tokens in the time it normally takes to generate one. You have traded a small amount of “cheap” compute (the Draft Model) for a massive gain in “expensive” latency reduction.
Implementing Speculative Decoding on GCP
To implement this on GCP, we need an architecture that can handle the tight synchronization required between the Draft and Oracle.
The most efficient way to do this is using JAX v0.4+ and Pallas on GKE. By using JAX’s sharding primitives, we can co-locate the Draft Model and the Oracle Model on the same TPU or GPU node. We want the “Speculation Loop” to happen in-memory, without any network round-trips between separate services.
On a TPU v5e, we can use Multi-Host Inference to split the memory. We dedicate a small slice of HBM for the Draft weights and the rest for the Oracle weights. We then use a custom Pallas kernel to orchestrate the verification step directly on the Tensor Cores, avoiding the overhead of the Python-to-C++ transition.
For those using vLLM v0.6+, speculative decoding is now a first-class citizen. You can launch a vLLM server with the --speculative-model flag, pointing to a smaller version of your base model. On GCP, we recommend using a Gemma-2-9b as the draft for a Gemma-2-27b oracle. This combination consistently yields 2x to 3x throughput improvements on standard text-generation benchmarks.
The Economic Payoff
Why should an executive care about speculative decoding? Because it fundamentally changes the TCO of your AI product.
Latency is the number one driver of user abandonment in agentic systems. If your agent takes 45 seconds to plan a trip, the user will just do it themselves. If you can reduce that to 15 seconds without buying any more hardware, you have effectively tripled the value of your existing infrastructure.
Furthermore, Speculative Decoding is Computationally Neutral. You are using the idle TFLOPS of your GPU (the 70% that was just waiting on memory) to run the Draft Model. You are not increasing your cloud bill; you are simply using the electricity you were already paying for.
In a competitive market where Every Token Matters (ETM), speculative decoding is the “Hidden Lever” that allows you to offer premium, high-reasoning models at the speed of a chatbot.
Beyond Linear Speculation: Tree-Based Verification
While standard speculative decoding follows a linear “guess 5 tokens, verify 5 tokens” path, we are seeing the rise of a more powerful paradigm: Tree-Based Verification.
In a linear model, if the Draft Model’s first guess is wrong, the remaining four guesses are immediately discarded, even if they would have been correct in another context. Tree-based verification allows the Draft Model to produce a “Tree of Speculations”—multiple possible branches of next tokens.
The Oracle Model then verifies all these branches in a single parallel batch pass. By using attention masks, the Oracle can calculate the probabilities for the entire tree simultaneously. This significantly increases the “Acceptance Rate” of the speculation. Instead of getting 2.5 tokens per pass on average, tree-based systems can often achieve 4 or 5 tokens per pass, pushing the speedup from 2x toward a theoretical 5x limit.
Medusa and Eagle: The Rise of Draft-less Speculation
One of the most exciting developments in speculative decoding infrastructure—available now on GCP’s L4 and H100 instances—is the Medusa architecture.
Traditional speculative decoding requires managing two separate models (the Draft and the Oracle). Medusa simplifies this by adding “Extra Heads” directly to the Oracle model. These heads are trained specifically to predict future tokens based on the current hidden state.
This is “Internal Speculation.” You don’t need a separate 7B model; you just use the top 1% of your existing model’s processing power to peer into the future. It eliminates the memory pressure of loading a second set of weights and simplifies the deployment pipeline on GKE. We’ve seen Medusa-style architectures deliver up to 2.2x speedups with zero degradation in output quality.
vLLM on GKE: The Deployment Manifest
To operationalize this on Google Cloud, we use the vLLM engine running on a GKE TPU-slice or GPU-pool. The configuration is surprisingly simple, handled through environment variables or command-line flags in your Kubernetes Deployment manifest.
apiVersion: apps/v1
kind: Deployment
metadata:
name: gemma-speculative-inference
spec:
template:
spec:
containers:
- name: vllm-server
image: vllm/vllm-openai:latest
args:
- '--model'
- 'google/gemma-2-27b'
- '--speculative-model'
- 'google/gemma-2-9b'
- '--num-speculative-tokens'
- '5'
- '--use-v2-block-manager'
resources:
limits:
nvidia.com/gpu: 4 # Running on L4 or A100 poolThis manifest tells vLLM to load the massive 27B model as the “Brain” and the 9b model as the “Scout.” The block manager handles the memory isolation, ensuring that both models share the same KV cache pool for maximum efficiency.
Designing for Latency-First UX
Finally, we must consider the user experience. When you achieve a 3x speedup in TTFT (Time-to-First-Token), you can change how you design your application.
Instead of showing a “Loading…” spinner, you can begin streaming the response immediately. You can implement “Speculative UI”—where the interface begins to render the predicted fields of a form before the Oracle has even finished the second sentence. This creates an “Instant AI” feel that mimics human thought. The combination of speculative decoding at the infrastructure layer and streaming at the UI layer is what defines the “Premium” AI experiences.
Speculative Decoding in the Real World: A Case Study
To grasp the impact, let’s look at a real-world scenario we implemented for a global financial services client.
The client was using a Gemma 2 27B model for complex document summarization. Their average latency was 18 seconds per document—too slow for their real-time trading desk needs. By introducing a Gemma 2 9B model as a speculative drafter on a shared GKE node, we achieved the following results:
- Baseline Latency: 18.2 seconds
- Speculative Latency: 6.4 seconds
- Token Throughput: Increased from 45 tokens/sec to 118 tokens/sec.
- Hardware Change: Zero.
The primary cost was a minor (4GB) increase in VRAM reservation to keep both models warm. For a production system handling 100,000 documents a day, this meant the difference between needing a massive, multi-million dollar TPU cluster and being able to comfortably serve the load from a standard GPU pool. This is the “Efficiency Dividend” that speculative decoding pays to the enterprise.
Conclusion: The Speed of Intelligence
We have spent the last two years obsessed with “making the models smarter.” The next two years will be about “making the models faster.”
Intelligence that is too slow to use is, for all practical purposes, not intelligent at all. Speculative Decoding is the bridge between the research lab and the real world. It is the infrastructure-level realization that the path to the future is not just bigger silicon, but smarter scheduling.