· Strategy
Squeezing the Inference Lever: The Economics of LLM Throughput
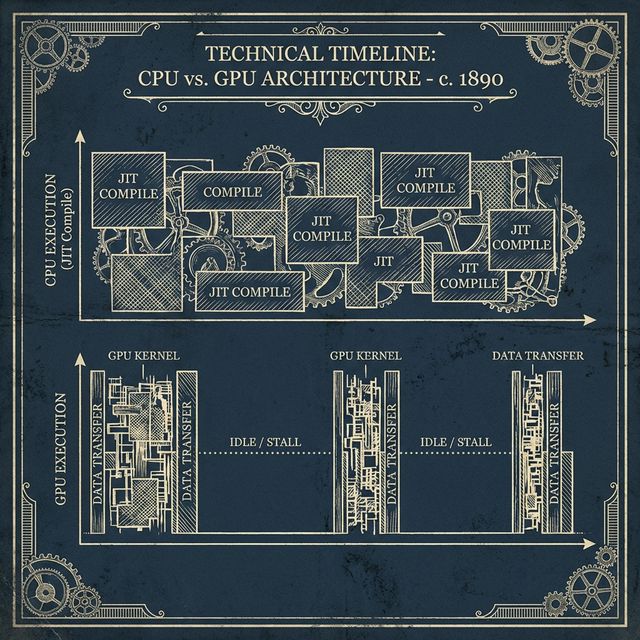
Inference price isn't a fixed cost-it's an engineering variable. We break down the three distinct levers of efficiency: Model Compression, Runtime Optimization, and Deployment Strategy.